̨���維�³���3DСоƬ�����Ǵ���1���ھ����GPU�Ĺؼ�
 С��ë
���ϱ༭����h��
�����ڣ�2024-04-03 17:46
С��ë
���ϱ༭����h��
�����ڣ�2024-04-03 17:46
|
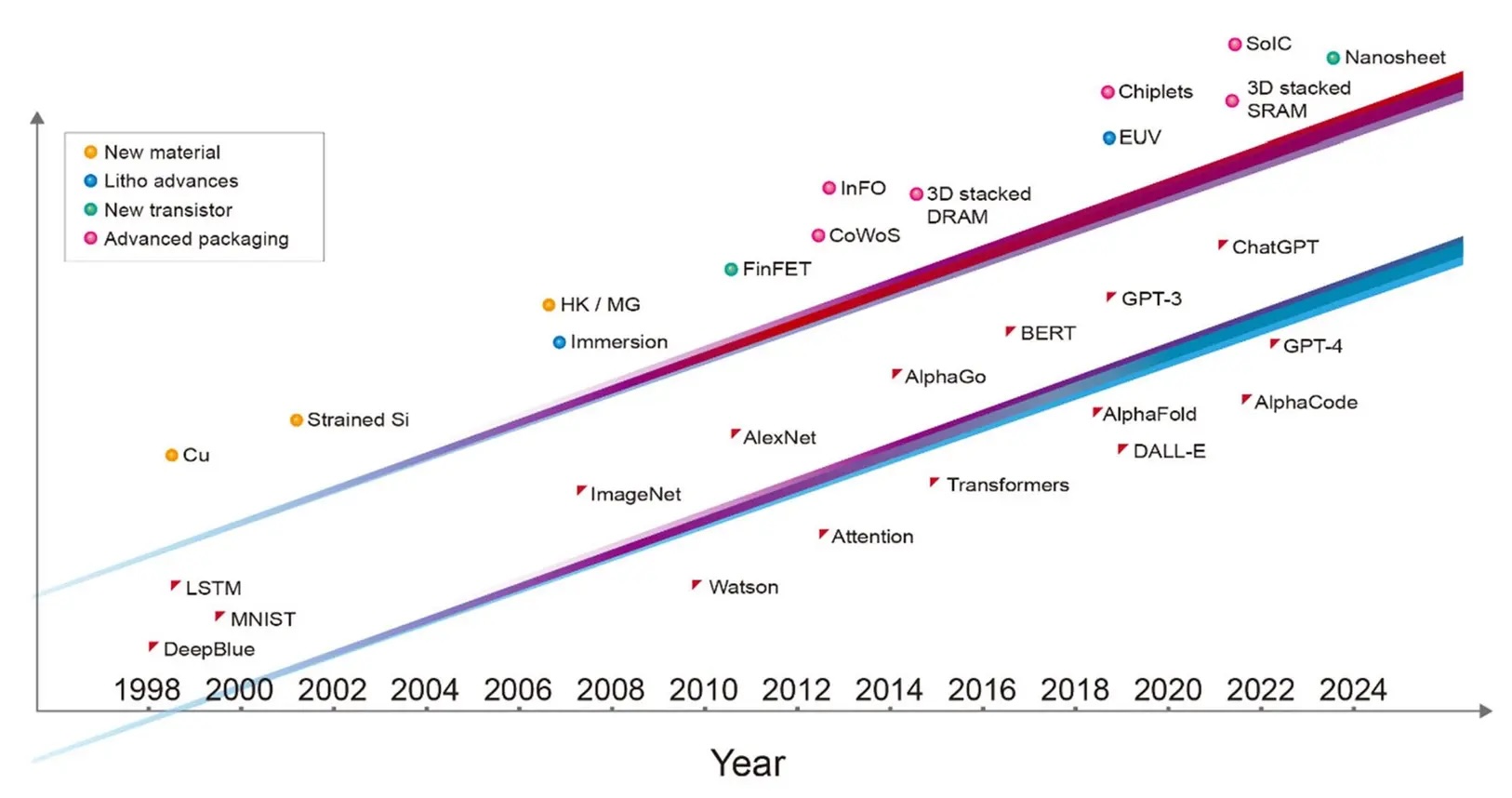
�ڽ��յ�IEEE Spectrum�����У�̨���維�³�����������ϯ��ѧ�һƺ�ɭ�����ʾ�������˹����ܵĿ��ٷ�չ���������ܶȸ��ߵ�GPU������������Ԥ�⣬δ����GPU����Ҫ����һ���ڸ�����ܣ��������ļ���ͻ�ƿ�����2030�����ʵ�֡� ��λ�߲�ָ�������ܾ���������������ӣ���Ŀǰ�ĵ�оƬ����ܵ��������Ƶ���ս�����Ĺ�������ԼΪ800ƽ�����ס��ⲻ�����������ɱ��������ڶ���������ʵ��һ���ھ���ܵ�Ŀ�ꡣ��ˣ�������Ϊ3DСоƬ������3D�ѵ�����ʵ�ִ�Ŀ��Ĺؼ���ͨ�������оƬ���ź͵�����һ�𣬿���ͻ�����м����ľ��ޣ�ͬʱ���ܽ�������ɱ��� �����л��ᵽ��3D�ѵ��������������������ڴ��ܶȣ���������������Ŀ�ģ�����AMD��3D V-Cache�����������СоƬ��Ryzen��Epycϵ��CPU�ϵ�Ӧ�á� ̨�������ʷ����ͼ��ʾ����2008�������������������Լÿ�˵�ʮ������ʮ������һ���ڵ�һǧ�ڣ��ٵ����NVIDIA��Blackwell GPUsͻ�Ƶ�һǧ�ھ�����ϰ�����֤������һ���ơ� ����̨����Ԥ����2034��ʵ��һ���ھ���ܵ�Ŀ�꣬��Ӣ�ض���ϯִ�й�Pat Gelsinger��ʾ����Ԥ����2030�꼴��ʵ�֡���̨����Ĺ۵�һ�£�GelsingerҲǿ����3D�ѵ��Ĺؼ��ԣ�ͬʱ�ἰ����Ribbon FETs�ͱ����Դ����Ⱦ���ܼ���ĸĽ��� ������һ���ھ����GPU����CPU������2030�껹��2034����������оƬ�����3D�ѵ�����������Ϊ�뵼����ҵδ����չ�Ĺؼ����� ԭ�ķ��룺"�������ʵ��һ��ӵ��1���ھ���ܵ�GPU ���� �뵼�弼���Ľ��������ƶ�AI�ķ���" ��1997�꣬IBM��������������������˹�����������ھ������˹�������dz��������������һ��ͻ���Ե�չʾ��Ҳ�Ǹ����ܼ����г�һ�տ��ܳ�Խ��������ˮƽ��һ�����������ڽ�������ʮ������ǿ�ʼ���˹�����Ӧ��������ʵ�������У����沿ʶ�����Է�����Ƽ���Ӱ����Ʒ�ȡ� �ٿ��ʮ���꣬�˹������Ѿ���չ�����ԡ��ϳ�֪ʶ���ĵز���������AI����ChatGPT��Stable Diffusion���ܹ�����ʫ�衢����������Ʒ����ϼ�������дժҪ����ͼ�������룬������Ƴ��������������ļ��ɵ�·�� �����˹����ܳ�Ϊ��������Ŭ�����������ֵľ������ChatGPT����һ���ܺõ����ӣ�չʾ��AI�����ʹ�����ܼ����������������Ϊ����ÿһ����������ô��� ������Щ���˾�̾��AIӦ�ö��鹦���������أ���Ч�Ļ���ѧϰ�㷨�Ĵ��¡�����������ѵ������������ݵĿɻ���ԣ��Լ�ͨ���뵼�弼������ʵ�ֵ���Ч���㷽��Ľ�չ�����������ռ����ϵõ���Ӧ�е��Ͽɣ������һ���������AI�����Ĺ���ȴ��Խ��١� �ڹ�ȥ����ʮ���AI����Ҫ��̱������ɵ�ʱ�����Ȱ뵼�弼���������ģ�û��������Щ��̱��Dz�����ʵ�ֵġ�Deep Blueʹ����0.6��0.35�ڵ�оƬ���켼�����ʵʩ��Ӯ��ImageNet������������ǰ����ѧϰʱ������������磬������40������ʵʩ�ġ�AlphaGoʹ��28����������Χ�壬�������ChatGPT�汾������5�����������ļ������ѵ�������ġ����µ�ChatGPT�汾����ʹ�ø��Ƚ���4�������ķ������ṩ���������������㷨���ܹ�����·��ƺ��豸�����������ϵͳ�漰��ÿһ�㶼��AI���ܵı�������������˵����������������������ƶ�������������Ĺؼ��� ���AI����Ҫ�������ֵ�ǰ�IJ�������ô������Ҫ�뵼����ҵ���������Ŭ������δ��ʮ���ڣ�������Ҫһ��ӵ��1���ھ���ܵ�GPU��������Ŀǰ������GPU���ʮ������ܵ�GPU��
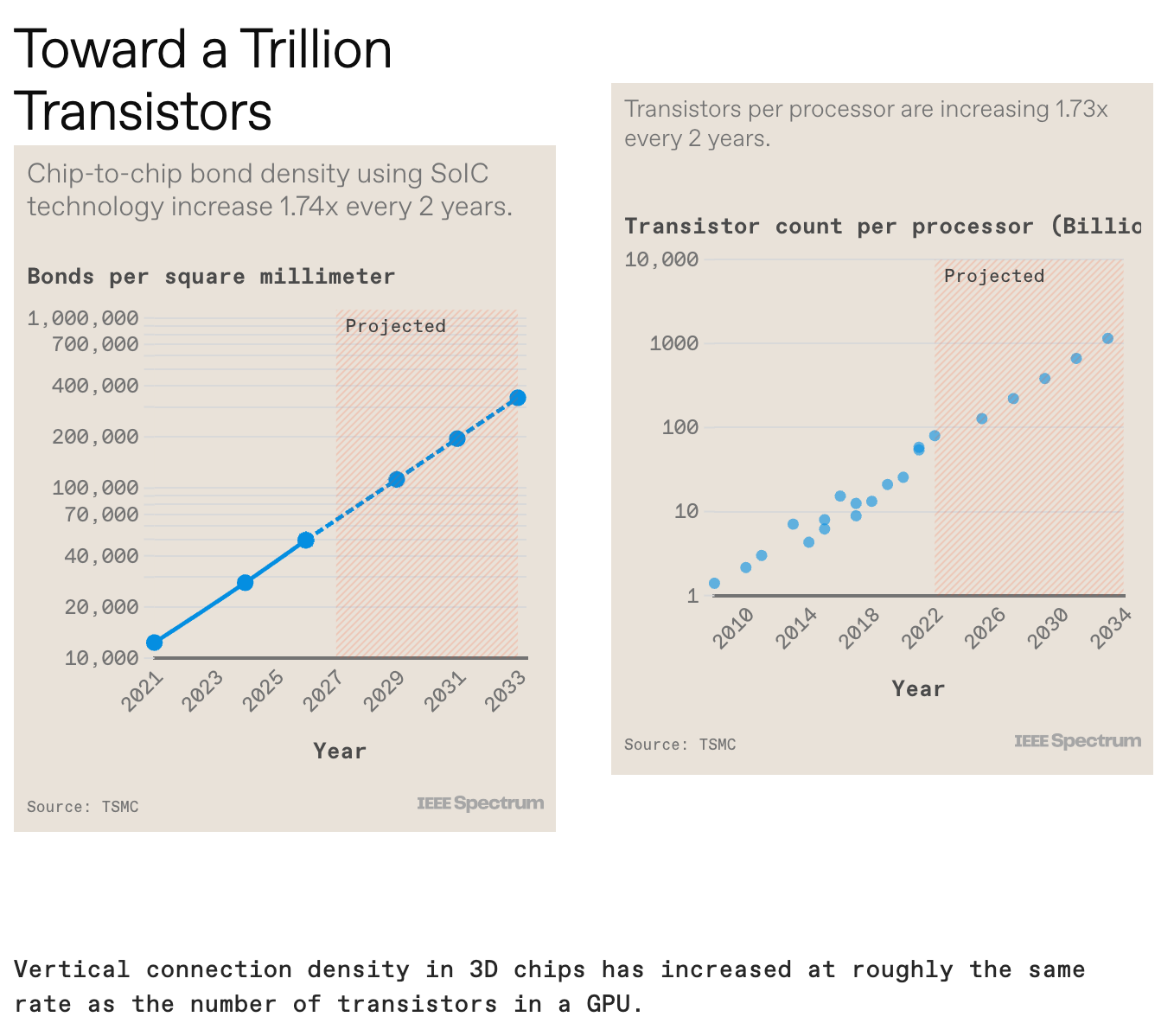
AIģ�ʹ�С���������� ��ȥ�����У�AIѵ������ļ�����ڴ�����������������������������磬ѵ��GPT-3��Ҫ�൱��һ���ڽ��г���50���ڴ����㣨��5,000 petaflops-days�����Լ�3�����ֽڣ�3 terabytes�����ڴ������� �µ�������AIӦ�ó�������ļ����������ڴ����������Ѹ������������������Ҫ�ش�һ�����ȵ����⣺�뵼�弼����β��ܸ�����һ���� �Ӽ�������������СоƬ �ԴӼ��ɵ�·�����������뵼�弼��һֱ��������С�����ߴ磬�Ա���ָ�Ǵ�С��оƬ���������ľ���ܡ��������������һ����Σ��������ڳ�Խ��ά���Ž�����άϵͳ���ɡ����������������оƬ��ϳ�һ���������ϡ��߶Ȼ�����ϵͳ�����ǰ뵼�弼�����ɵ�һ����ʽת�䡣 ��AIʱ����ϵͳ�Ĺ���ֱ�����伯�ɵľ�������������ȡ���Ҫ������֮һ�ǹ����оƬ���߱���Ƴ�ֻ��������Լ800ƽ������IC���������ν����ģ�����ơ����������ǿ��Խ�����ϵͳ�ijߴ���չ�����������ģ������ơ�ͨ��������оƬ���ŵ�һ���ϴ���н�㡪��һ���Ƭ�����н��л����������ǿ��Լ���һ�������ȵ���оƬ�������ɶ�ö���豸��ϵͳ�����磬̨����ľ�Բ��оƬ��װ��CoWoS�������������ɶ��������ģ������ļ���оƬ���Լ�һ��ߴ����ڴ棨HBM��оƬ�� HBMs����һ����AIԽ��Խ��Ҫ�Ĺؼ��뵼�弼����ͨ���ڶ����ѵ�оƬ������ϵͳ��������������̨�����֮Ϊϵͳ����оƬ��SoIC����HBM��λ�ڿ�����IC�����Ĵ�ֱ����DRAMоƬ��ջ��ɡ���ʹ�ó�Ϊ����ͨ�ף�TSVs���Ĵ�ֱ��������ȡÿ��оƬ���źţ���ͨ�������γɴ洢оƬ֮������ӡ����죬������GPU�㷺ʹ��HBM�� չ��δ����3D SoIC���������ṩһ�֡������������������ȡ����ͳHBM�������ڶѵ���оƬ֮���ṩ���ܼ��Ĵ�ֱ����������Ľ�չ��ʾ��ʹ�û�ϼ��ϣ�һ��ͭ��ͭ���ӣ����ܶȸ��ں��������ṩ�ģ���HBM���Խṹ����12���оƬ�ѵ����ڸ���Ļ�����оƬ�������º��ӣ����ִ洢ϵͳ���ܺ�Ƚ�Ϊ600�ס� �ɴ�����Ƭ���д���AIģ�͵ĸ����ܼ���ϵͳ���ʱ����������ͨ�ſ��ܻ�Ѹ�����Ƽ����ٶȡ����죬��ѧ�����Ѿ��������������ĵķ������������ӡ����ǽ��ܿ���Ҫ���ڹ����ѧ�ġ���GPU��CPU��װ��һ��Ĺ�ѧ�ӿڡ��⽫�������������Ч�ʸߵĴ�������ֱ�ӵĹ�ѧGPU��GPUͨ�ţ�ʹ������̨�������ܹ���һ̨���ͳһ�ڴ��GPUһ����������������AIӦ�õ��������ѧ����Ϊ�뵼����ҵ����Ҫ�ĸ��ܼ���֮һ�� ����һ��ӵ��1���ھ���ܵ�GPU ����ǰ���ᵽ�ģ�����AIѵ���ĵ���GPUоƬ�Ѿ��ﵽ����ģ�����ơ����ǵľ��������ԼΪ1000�ڸ����������Ӿ�������������ƽ���Ҫ���оƬ��ͨ��2.5D��3D���ɽ��л�������ִ�м��㡣ͨ��CoWoS��SoIC����ظ���װ�������ɵĶ��оƬ������ʵ�ֱȵ���оƬ���ܼ���ľ����������ö��ϵͳ������Ԥ�⣬��δ��ʮ���ڣ���оƬGPU��ӵ�г���1���ھ���ܡ� ������Ҫ��������ЩСоƬ����ά��ջ���������������˵��ǣ�ҵ���Ѿ��ܹ�Ѹ����С��ֱ�����ļ�࣬�Ӷ��������ӵ��ܶȡ����һ��кܴ�Ŀռ���Լ�������������Ϊû��������Ϊ�����ܶȲ�������һ�����������������ࡣ
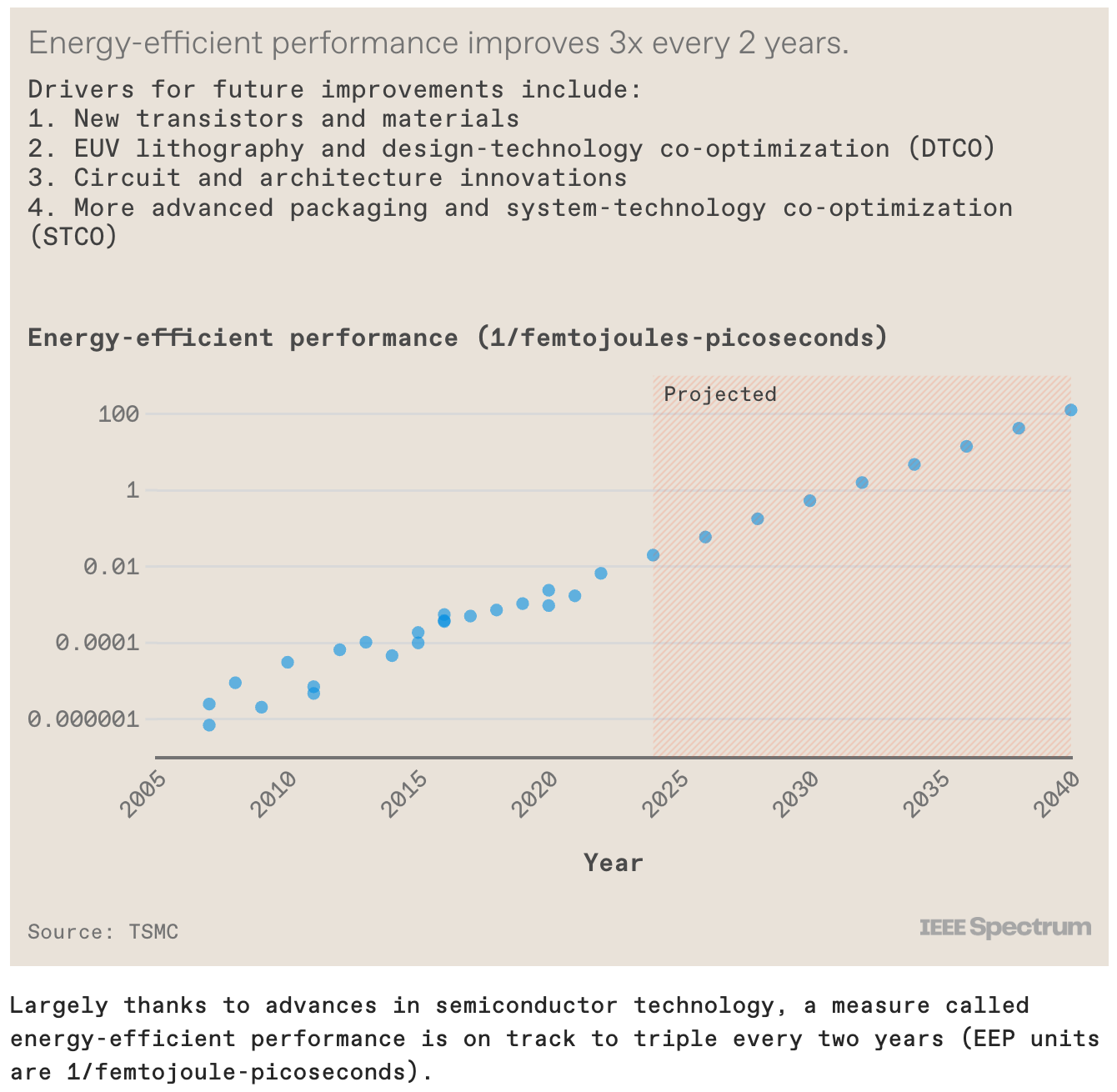
GPU������Ч���������� ��ô��������Щ���µ�Ӳ����������ι�����ϵͳ���ܵ��أ� ������Dz鿴������GPU�����ƣ����ǿ��Կ����ڱ���Ϊ����Ч�����ܣ�EEP����ָ�����Ȳ���ߡ�EEP��һ������ϵͳ��ԴЧ�ʺ��ٶȵ��ۺ�ָ�ꡣ�ڹ�ȥ��15����뵼����ҵÿ����ͽ�����Ч�����������Լ����������������һ���ƽ�����ʷ���ʼ�����ȥ���⽫�ɰ����²��ϡ������ͼ��ɼ����������⣨EUV����̡���·��ơ�ϵͳ�ܹ�����Լ�������Щ����Ԫ�ص�Эͬ�Ż����ڵ����ഴ��������
�ر��ǣ�EEP�����ӽ����������������۵ĸ���װ�������ƶ������⣬����ϵͳ����Эͬ�Ż���STCO�������ĸ������GPU�IJ�ͬ���ܲ��ֱ����뵽�����Լ���СоƬ�ϣ�����ʹ�ø��Ե���ѱ��ֺ���õļ������й����������Խ��Խ��Ҫ�� 3D���ɵ�·��Mead-Conwayʱ�� 1978�꣬��������ѧԺ���ڿ�����÷�º�Xerox PARC���ֶ�����Τ������һ�ּ����������Ƶļ��ɵ�·����������ʹ��һ����ƹ���������оƬ���ţ��Ա㹤��ʦ�����ڲ������˽�ռ�������������ɵ���Ƴ����ģ���ɵ�·��VLSI����·�� ͬ�����͵���������3DоƬ�����˵����Ҫ�ġ����죬���ʦ��Ҫ�˽�оƬ��ơ�ϵͳ�ܹ���ƺ�Ӳ���������Ż�����������Ҫ�˽�оƬ������3D IC��������װ����������������1978�������������������ٴ���Ҫһ����ͬ��������������Щ�������Ա������ƹ����ܹ����⡣������Ӳ���������Խ������ʦ�ṩһ�����ɵ���ȥ����3D ICϵͳ��ƣ����۵ײ㼼����ʲô�����Ѿ���·���ˣ�һ����Ϊ3Dblox�Ŀ�Դ���Ѿ������������Ƽ���˾�ͼ�����˾���ܡ� ͻ���������������δ�� ���˹�����ʱ�����뵼�弼�����ƶ������˹�����������Ӧ�õĹؼ�����������һ��GPU���ٱ��������ڹ�ȥ�ı��ߴ����̬���°뵼�弼���Ѳ��پ������ڶ�άƽ���ϳ�����С��һ������ܡ�ͨ���������ܶ�Ľ��ܾ���ܡ�ר�ż��㸺�صĸ�Чϵͳ�ܹ��Լ���Ӳ���Ż����л����,���Թ��������ɵ��˹�����ϵͳ�� �ڹ�ȥ�����������뵼�弼���ķ�չ������һ����ֱ��������ǰ�У���չ����һĿ��Ȼ����С����ܳߴ������ȷ�ļȶ�Ŀ�ꡣ ����������߳�������������δ���ĵ�·���������������չ���Ѷ�Ҳ�����վ��������ǣ�����֮����һƬ��������أ��뵼�弼�����ٱ���ȥ���������ޣ�������ӱ�Ŀ����������������֡� |
ԭ����Ŀ

 Ӳ������ʷ
Ӳ������ʷ


�ʼDZ��ȵ�

�ʼDZ���Ƶ
IT�ٿ�
�ʼDZ��ȴ�

��������
�۳�ֵ•��ѡ
-

- ����ʼDZ����� �콢���i5 14Ӣ��air�ᱡ�����������ð칫ѧ��������᱾ ���� ���i5 8G�ڴ� 512G��̬ ���ٹ�̬ ǧ������ֱ�� һ������
- ��1000��200
-
��3399.0
��3499.0

- Apple/ƻ��2022��MacBookAir�������Żݡ�13.6Ӣ��M2(8+8��)8G256G��ɫ�ᱡ�ʼDZ�����MLXY3CH/A
- ȯ��ʡ500
-
��7699.0
��8199.0

- HUWI ���С�2024��Ӣ�ض���ѡ��������ʼDZ������ᱡ����ѧ�����������ѧϰ����칫��Ϸ���� ����Ӣ�ض��ĺ�+13�� IPS��խ��ȫ����+������ 32G����+1024G����Ӳ��
- ȯ��ʡ130
-
��2578.0
��2708.0

- ����(Lenovo)С��һ��̨ʽ������23.8Ӣ��(R5 5500U 8G 512G SSD ����ͷ win11 )��
- ȯ��ʡ10
-
��3089.0
��3099.0

- BIGME inkNoteS˫����ͷ���ܰ칫�� 10.3Ӣ��īˮ����ֽ����д�ʼDZ��������Ķ���
- ȯ��ʡ50
-
��2649.0
��2699.0
-

- ����ʼDZ�����С��Pro14 AI���ܱ� �����ܱ�ѹ���Ultra5 14Ӣ���ᱡ�� 32G 1T 2.8K OLED��ˢ�� ��
- ȯ��ʡ10
-
��5989.0
��5999.0

- HUVVE�ٷ�2024��14��Ӣ�ض�+���i7���ԡ��ʼDZ�����4K�ᱡ����ѧ����������칫�����Ϸ����������� ��Ӣ�ض��ĺˡ�13�� IPSխ��ȫ����+������ 8G����+128G����Ӳ��
- ȯ��ʡ100
-
��1297.0
��1397.0

- ThinkPad X1 Nano 11�����i5Ӣ�ض�Evoƽ̨13Ӣ���ᱡ�ʼDZ����� 11��i5 16G 512G 4G���� 0CCD
- ȯ��ʡ20
-
��7979.0
��7999.0

- ��Ħ��(GMK)K1 6800H AMD R7 ��������Ϸ�칫�ڴ�mini��������̨ʽ���� 16G+1TB��̬
- ȯ��ʡ800
-
��3299.0
��4099.0

- ��е������14Pro 2024�콢������7 7840HS��ˢѧ����Ϸ�� AI����R7-8845HS��ɫ����ư칫�ʼDZ����� R7-7840HSح2.8K+120Hzȫ���� 16G�ڴ� 1TB��̬����
- ȯ��ʡ300
-
��4699.0
��4999.0
-

- Apple/ƻ��2023��Mac mini���������������Żݡ�M2 Pro��10+16�ˣ�16G 512G ̨ʽ��������MNH73CH/A
- ȯ��ʡ300
-
��8899.0
��9199.0

- Apple/ƻ��2020��MacBookAir13.3Ӣ��M1(8+7��) 16G 256G��ɫ�ᱡ�ʼDZ����� Z127000CF�����ơ�
- ȯ��ʡ800
-
��8699.0
��9499.0

- Apple/ƻ�� iPad Air(�� 5 ��)10.9Ӣ��ƽ�� 2022��(256G 5G��/MMEX3CH/A)��ɫ ��������
- ȯ��ʡ400
-
��6799.0
��7199.0

- �伫 ��� i5 12400F/��˶GTX1650���ʦ������Ϸ�羺�칫̨ʽȫ��������װ��������DIY���� 12400F+GTX1630 4Gح���ö�
- ÿ��3499��600
-
��3599.0
��3699.0

- Apple/ƻ��2022��MacBookAir13.6Ӣ��M2(8+8��)16G 512G ��ɫ�ᱡ�ʼDZ����� Z15W0003H�����ơ�
- ȯ��ʡ1500
-
��10499.0
��11999.0
-

- ����(SAMSUNG)S9 Ultra 2023��ƽ�����14.6Ӣ������8Gen2 120Hz 12G+512GB WIFI��ѧϰ�����ر���Ӱ��
- ȯ��ʡ10
-
��8889.0
��8899.0

- ����ʼDZ�����С��Pro14���ܱ� �����ܱ�ѹӢ�ض����i5 14Ӣ���ᱡ�� 16G 1T 2.8K��ˢ������ ��
- ȯ��ʡ10
-
��4789.0
��4799.0

- Apple/ƻ��2023��MacBookAir 15Ӣ�� M2(8+10��)8G 256G��ջ��ᱡ�ʼDZ�����MQKP3CH/A
- ȯ��ʡ1300
-
��9199.0
��10499.0

- ����ʼDZ�����С��14������ �����ܱ�ѹ���i5 14Ӣ���ᱡ�� 16G 512G ��ѣ���� �� �칫ѧ������
- ȯ��ʡ10
-
��3989.0
��3999.0

- Apple/ƻ���������Żݡ�iPad 10.2Ӣ��ƽ����� 2021��(256GB 5G��/MK633CH/A)��ջ�ɫ ��������
- ȯ��ʡ800
-
��3939.0
��4739.0








�ʼDZ����Ա���

