ʧҵԤ������AI�����۾����������ͣ��ּ���ȡ���������λ
 ������
�༭�� ��h��
�����ڣ�2023-10-10 17:49
PConlineԭ��
������
�༭�� ��h��
�����ڣ�2023-10-10 17:49
PConlineԭ��
|
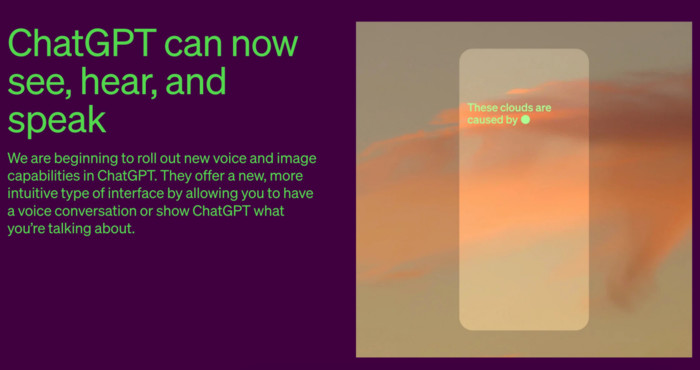
����ChatGPTӭ���ش���£�������������ͼ��ʶ���ܣ��û�����ֱ����ChatGPT���������Ի����ϴ�ͼƬ��AI�����������������������ݣ����൱��ΪAI�������۾����������ͣ�Ҳ����ChatGPT�Ķ�ģ̬������OpenAI��������ʾ��Ƶ�����ܵ���������ʧҵԤ����
����Ƶ�У��û�������һ����Ƭ����ChatGPT��ͬʱ����ˡ�������Ұ����г������ηŵ�һЩ��������Ȼ��ChatGPT�����˻ش���˵��һ����Ҫ�ҵ���λ����Ŀ����ͷŸ˻�����˨������п����ͷŸ˴����Ϳ��ԣ��������˨������Ҫһ�������ǰ��֡�����������λ���»���������Ҫ�ĸ߶ȣ���š����˨������ͷŸˣ�ȷ����λ�Ѿ��̶�����ȷ����λ�ij�������ȷ�ģ�����ζ������ChatGPT��ʾ��������й��ߣ�����չʾ���������������������һ����
���������û�����Ƭ�ֲ�Ȧ���������·�����˨λ�ã�����ChatGPT����������Dz��ǿ����ͷŸˡ�ChatGPT�ظ��ⲻ��һ���ͷŸˣ�����һ����˨������Ҫһ�������ǰ���š������Ȼ��Ϳ��Ե�����λ�ĸ߶ȣ�ȷ����λ��������ȷ��ƽֱ�ģ�����˨š��������˵�����
Ȼ���û����ϴ���˵������Ƭ��������Ƭ����ChatGPT����������û����ȷ�Ĺ��ߡ�ChatGPT�ظ�������ȷ�Ĺ��ߣ����㹤�������࣬��һ�����š�DEWALT���Ĺ�����װ����Ҫ�ҵ�4mm�������ǰ��֣�Ȼ�������ɿ���λ�������˨���������θ߶ȣ�������š���� �������ʣ�ӵ���ˡ��Ӿ����Ժ��AIչ�ֳ������������൱ը�ѵġ�����ǰ��AI��ֻ����в������Ա����ʦ�����ݷ���ʦ���İ��༭���ظ��Թ����϶࣬�������̱Ƚ�ȷ���Ĺ����Ļ��������������Ӿ���AI��ֱ����в��ÿһ��������λ�� һ����AIǿ��Ĺ��ܣ���������ͨ�˽���ܶ�רҵ���⣬���ǿ���ͨ���Ի���AI����Ч�Ľ�����ͬʱ���ܽ����������������ݣ�ֱ����AI��������ʹ���û���AI�Ľ���������Ȼ������������һ�����������֣����������Ƕ���һЩ��ѯ����������� ��һ���棬ChatGPT��ǿ���Ӿ�����������Ҳ��AI�ڸ��������ȡ������������� ��������һ��166ҳ�IJ������棬����ϵͳ�����ۺͷ�����OpenAI���¶�ģ̬����ģ��GPT-4V���Ӿ���GPT-4�����ñ����Ϊ11���½ڣ��Ӷ��ά��ȫ�濼��GPT-4V�������;��ޣ�������������������ģ��ģ̬ģ�͵Ĺ������ơ� �������ȸ�����GPT-4V�Ľṹ�����������Դ����ı�������������ͼ����Ϣ��Ȼ������ϸ�о��˸����������������GPT-4V�ڲ�ͬ�����ϵı��������ͷ������������Է��֣�GPT-4Vӵ��ǰ��δ�еĴ������Ҷ�ģ̬��������������书�ܸ߶�ͨ�ã��ɷ�������������Ϊһ��ǿ��Ķ�ģ̬ͨ��ϵͳ�� �����ر�������GPT-4V��ͼ��Ķ���������������ܴ����µ��˻�������ʽ������ʹ���Ӿ����ݽ�����ʾ�������̽���˻���GPT-4V��DZ��Ӧ�ó������Լ�δ���з����Ƚ���ģ̬ģ�͵ķ���������ԣ����о���GPT-4V�����˱Ƚ�ȫ��IJ��Ժͷ�������˶Դ��ģ����ģ�������Ƶ����⣬Ҳ���ٽ�δ����ģ̬�˹����ܼ����ķ�չ�� ���������ǽ�ѡ�˼���GPT-4V������Ӧ�ó����еİ�����������ҷ���һ�¡� ͼ��ʶ��
����ʶ��GPT-4V�����ܹ�ʶ���ͼƬ�е�������˭�����һ���������Ƭ������������ʲô���������·���ͼƬ��������ʶ�������������������ͳ�����һ����������ڽ�̨�ϣ������ڷ����ݽ����������ݽ��ij��ϣ�Ϊ2023�����ձ��㵺���е��߹����ŷ�ᣡ�Ҳ���Ƭ�е�����NVIDIA����ϯִ�йټ����ϴ�ʼ�˻���ѫ�����������Ų�չʾNVIDIA�IJ�Ʒ���ܿ�����ͼ�δ�����Ԫ��GPU����
�ر�ʶ��GPT-4V��ȷ��ʶ���˲���ͼ���еĵرꡣ������������������ϸ�����������ر�ľ��衣
ʳ��ʶ��GPT-4V����ʶ����ֲ��ȡ���������ʶ�����ͼ���д��ڵ��ض�ʳ�ġ�װ��Ʒ����⿼�����
ҽ��ͼ����������GPT-4V�ܹ�ʶ���ṩ��X��Ƭ�е����ݺ��ǣ������������·������·����dzݲ���¶��������Ҫ�γ���
ҽѧͼ����������GPT-4V����ʶ����Jones���������ij�����֢�������Ի���CTɨ��ķβ�ָ��DZ�ڵ����⡣
������ͼ�����������GPT-4V�ܹ����ɲ�ͬ���Ե�ͼ��������GPT-4V��һ������ģ�ͣ���������������ɶ������ԣ�����ͼ������������ζ���������ڲ�ͬ����֮������ͼ�������������ڿ����Խ�������Ϣ�����dz����á� ͨ���⼸�����������Կ���GPT-4VӦ��DZ���dz�����Ӧ����ҽѧӰ����ĸ�����ϣ�����������ȷ�ԣ�Ҳ���������Ч�ʡ�Ӧ�������λ��߲�����У������ṩ���õ������������飬���������ܹ����ɲ�ͬ���Ե�ͼ���������Ե�����ɺܴ����ս�� ƪ�����ޣ�����ֻ�ǽ�ȡ�����м���������ԭʼ����https://arxiv.org/pdf/2309.17421.pdf�� ���֮ǰ���ṩ�Ի����ܵ�AI�������Ӿ���GPT-4������൱ǿ��!��������һ����,������һ��˼ά��,�ٹ��뺣����֪ʶ,�����ָ������۾�����������,���Ϳ���������һ��ֱ�Ӵ���ͼ����Ƶ���Ӿ���Ϣ,���ⳡ���Ͷ���,��������������������������Ӿ�������GPT-4�ܹ����ж�ģ̬�Ľ�����ѧϰ���������ܻ�����������ࡣ �������GPT-4��ӵ�������������ֱ۵Ļ�е���ơ�֫�塱,���Ϳ���ֱ�Ӳ�����������,���и����ӵ�̽����ʵ�����⽫�����������ȡ��ʵ����֪ʶ���������䱸�������ġ�֫�塱��������GPT-4�γɶԻ����ĸ�֪,ӵ�и��ḻ�Ľ�����ʽ�� ��Ȼ,���ǻ���Ҫ�����GPT-4��������֪ʶ����������ģʽƥ������⡣����ȷ����������ȷ��֪������ǿ��,�����DZ����û�����˺�������Ը����εķ�ʽ������չGPT-4,�������ų�Ϊһ���������˹�ͨ��������������һ���� |

ԭ����Ŀ

 Ӳ������ʷ
Ӳ������ʷ


�ʼDZ��ȵ�

�ʼDZ���Ƶ
IT�ٿ�
�ʼDZ��ȴ�

��������
�۳�ֵ•��ѡ
-

- ����ʼDZ�����V15 11�����С��Ʒ���ᱡ�� 15.6Ӣ��ѧ��������ư칫��Ϸ�� ȫ������i3-1115G4 20G�ڴ� 512��̬ IPSȫ������ ��Ϸ�������Կ� ȫ�ߴ���� �ǿջ�
- ����Ʒ
-
��2899.0
��2999.0
- Apple/ƻ�� iPad Pro 12.9Ӣ��ƽ����� 2022���(128G 5G��/MP293CH/A)��ɫ ��������
- ȯ��ʡ600
-
��9899.0
��10499.0

- Apple/ iPad(�� 10 ��)10.9Ӣ��ƽ����� 2022���(64GB WLAN��/ѧϰ�칫����/MPQ03CH/A)��ɫ
- ȯ��ʡ300
-
��3299.0
��3599.0

- ThinkPad ����ThinkBook 16+ 13��Ӣ�ض�Evo���ѹ������ 16Ӣ���ᱡ�ʼDZ����� 2.5K ��������i5-13500H 16G 1T 0LCD
- ȯ��ʡ20
-
��6179.0
��6199.0

- С��ƽ��6 Max 14Ӣ��2023�¿����ƽ����Զ���һXiaomiPadѧ������ѧϰ���ְ칫��Ϸ ��ɫ 12GB+512GB
- ȯ��ʡ50
-
��4349.0
��4399.0
-

- ��˶��ѡ5 Pro ������ 16Ӣ��羺��Ϸ�� �ʼDZ�����(R9-7940HX 16G 1T RTX4060 2.5K 165Hz ��ɫ��)��
- ȯ��ʡ10
-
��7989.0
��7999.0

- ����������R9000P 16Ӣ����Ϸ�ʼDZ�����(8��16�߳�R7-6800H 16G 512G RTX3060 2.5k 165Hz��ɫ��)��
- ȯ��ʡ10
-
��9989.0
��9999.0

- ������������AMD R5 -5600�������С����6�˸�������Ϸ��������칫��Я���ø��������ϵ��� R5-5600H ���
- ȯ��ʡ200
-
��1230.0
��1430.0

- ����Ӫ������������Y700ƽ�� 2023�� 8.8Ӣ����Ϸƽ�� ��ˢ2.5K������8+Gen1������ר�����ΰ칫ƽ��
- ȯ��ʡ137
-
��2298.0
��2735.0

- �챵AOOSTAR GEM12�������� ���������ܵ������� �羺��ϷС�Ϳڴ���Я����MINĮʽ���䱸OCuLink�ӿ� AMD R7-8845HS����������ָ�ơ� ϵͳ�����ڴ���Ӳ�̡�
-
��2699.0
��2999.0
-
- С�ȴ���ѧϰ��P20Pro��ѧ��(6+128G)15.6Ӣ��Сѧ������ѧ��ƽ����� �ٶ����Ĵ�ģ�� AI��ѧ���ļ�
- ȯ��ʡ5
-
��3894.0
��3899.0

- ����ʼDZ�����V/S14 ʮһ�����i5�콢�� 14Ӣ����Լ۱ȳ��ᱡ���ð칫���ѧ������ȫ�ܱ� 14��16G�ڴ� 512G��̬ IPSح���� ����������Կ� ���ٹ�̬��win10/11�������
- ȯ��ʡ50
-
��3749.0
��3799.0

- ���գ�hp��ս66���� 2023����ᱡ���ʼDZ����� ����칫����ѧ�������Ϸ��������� ���� 15.6/i5-1340P ���� | 2.5K�� 16G 1T��̬ ��䳤����+23��ȫ��13��
- ȯ��ʡ200
-
��4099.0
��4299.0

- ��е���������С��������5600H/5800H�����ܳԼ�LOL��Ϸ�칫���3����ʾ/����MINI���� R5-5600H ϵͳ(���ڴ�Ӳ��ϵͳ)
- ȯ��ʡ10
-
��1179.0
��1189.0

- ����(Lenovo)��������7000K 2023Ӣ�ض����i7��Ϸ��������(13��i7-13700KF RTX4060Ti 8GB�Կ� 16G 1T SSD��
- ȯ��ʡ10
-
��9289.0
��9299.0
-

- ��Ħ�͡�GMK����Ħ��K6 ������������ 7840HS 65W����������7 ��Ϸ�칫���miniС���� ���ѽ���ɫ 32G+512GB��̬
- ȯ��ʡ300
-
��2999.0
��3299.0

- ����ʼDZ�����С��Pro14�ᱡ�� 14Ӣ�糬�ܱ�(�����ܱ�ѹR7-7735HS 16G 1T 2.8K��ˢ��)�� ����칫ѧ����Ϸ
- ȯ��ʡ10
-
��5789.0
��5799.0

- ����ս��S6 ���i5 12400F/13400F/4060Ti���ʦ��Ϸ̨ʽ����װ������������ ������ i5 13400F RTX3060 8G
- ȯ��ʡ600
-
��4499.0
��5099.0

- ��˶ Ӱ13/14��i7 14700KF�Լ�������ֱ�����ʦ�羺��Ϸ̨ʽ��������diy��װ���� �����ح��i7 14700KF/RTX4060
- ȯ��ʡ800
-
��7599.0
��8399.0

- ��������ʼDZ�����С��16 Ӣ�ض����ѹi5 16Ӣ���ᱡ�� 16G 512G������ ����칫ѧ��
- ȯ��ʡ10
-
��3989.0
��3999.0



�ʼDZ����Ա���

